The first recommendation is to use a separate database for each microservice. This way, you can limit the number of writes and reads required to access the data by each microservice, which will increase performance. Also, having a separate database allows you to take advantage of existing technologies and techniques such as sharding, replication and backups that are already in place at your company.
You might be thinking, “What about the cost?” But don’t worry; there are ways to reduce those costs considerably. You can use one database for read-only operations and another for write-only operations or even use an existing NoSQL database for both read-only and write-only operations.
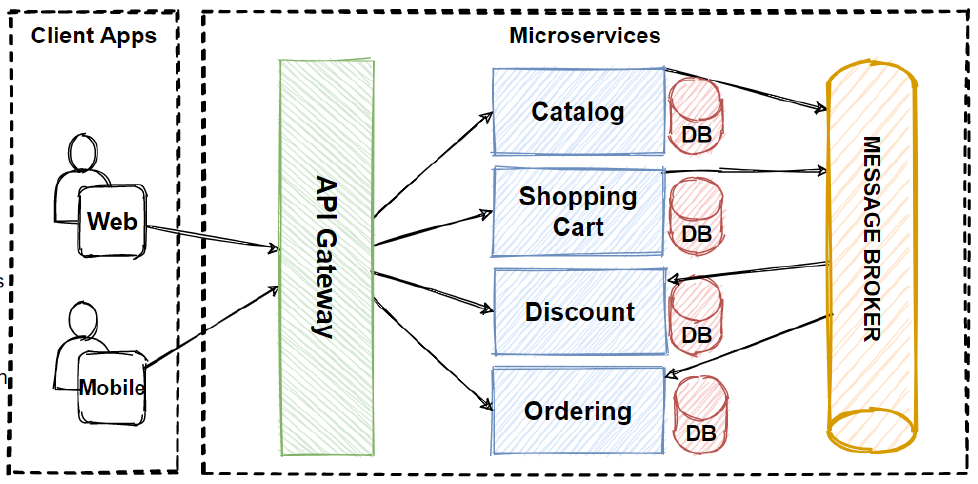
Separate Database For Each Microservice
In one of the previous articles, we discussed about the benefits of microservices architecture and how to implement it. We also discussed about how to separate data from code. In this article, I will share how to separate database for each microservice.
The database per service pattern is a microservices architecture design pattern where each microservice has its own database. The idea is to have one to many relationship between microservices which makes it easier to manage the data and scale up as needed.
The advantages of this design are:
It’s easy to scale up when needed, because each service has its own database
Each service can be managed independently and the data can be shared between other services through APIs or message queues
You can use different databases for different types of services, like NoSQL databases for storing events, logs or user data and relational databases for storing transactional information
A single database for all microservices is a common mistake. It’s better to have separate databases for each microservice, so that each can have its own schema, performance, and structure.
In this article, we are going to discuss why we should use separate databases for microservices and how to do it in Spring Boot.
microservices architecture pattern
In the microservices architecture pattern, each service is responsible for a specific business function and has its own database. Each microservice has a different set of requirements, which means they may need their own schema, performance and structure.
One To Many Relationship In Microservices Architecture
A database per service can be a good way to go, but again, it depends on your situation. It brings some benefits over having one database for all your microservices:
One-to-many relationships (e.g. an employee can belong to many departments) are easier to implement with a separate database because you can have different tables for each relationship.
You can have different schemas for each microservice, which makes it easier to keep track of changes in the schema and define custom data types per microservice.
If you want to share data between two microservices, you would have to expose the information through an HTTP endpoint and use Spring Data for example. As soon as you have more than one microservice doing this, it becomes difficult to keep track of all these endpoints and also easy to make mistakes when updating them.
Microservice architecture is a software development approach in which a software application is divided into small, independent services.
Microservices are independent and can be deployed individually to promote scalability, testability and maintainability.
The following are the basic concepts behind microservices:
Each microservice has its own database. The data in this database is owned by that particular microservice. Each microservice has its own codebase, deployment and life cycle. Each microservice has its own team working on it.
In microservices architecture, the database is a shared resource. This means that all of the services in your application can access and modify it. This approach is often called a shared database or shared schema.

The database per service pattern is an alternative to using a shared database. In this pattern, each microservice has its own database instance. A service may have one or more databases depending on its complexity and requirements.
This article explores why you might want to use multiple databases in your microservices architecture, and how you can implement it using Spring Boot as an example.
There are different approaches to database design in microservices architecture. The most common approach is to have a separate database for each service, which is also known as “database per service” pattern. This is because it allows you to scale your database independently from the rest of your application, which allows you to scale up or down as needed.
The other option is to share a single database between all services. However, this approach can be difficult if you need multiple instances of the same data (such as user profiles). It also makes it harder to scale up and down because everything is stored in one location.
In this blog, we are going to discuss the database per service pattern. It is one of the most popular techniques used by developers to implement microservices architecture.
Let’s take an example to understand how it works. Suppose we have two microservices. One is responsible for the login and signup process, while the other handles billing details. In this case, we can create two databases: one to store user data and another one to store billing information.
In this way, we can avoid sharing any data between these two services as they operate independently from each other. This makes our system flexible and scalable as well as efficient.
The database per service pattern is the most common architecture for microservices. This architecture is great because it allows you to have different databases for different services and maintain complete isolation between them.
The database per service pattern also makes it easier to scale each service separately, since you don’t need to worry about scaling the shared database.
One of the challenges with this approach is sharing data between microservices. For example, if one microservice needs some data from another microservice, there are several options for how you can handle this:
Use a shared database, which means that all your services need access to all data. This may not be acceptable in some cases (especially if the data is sensitive), so you should only use this approach if absolutely necessary.
Use a message queue like Kafka or RabbitMQ and use the pub/sub mechanism. In this case you don’t need any direct communication between your microservices, but instead use messaging queues for sending and receiving messages between them.

Use REST APIs to send requests and receive responses from other services. You could also use asynchronous calls using promises or callbacks instead of returning responses directly from your service methods.
Single database vs multiple databases:
One of the biggest advantages of using a single database is that there is no need to worry about sharding, replication and failover. A single database means less infrastructure to maintain and manage.
On the other hand, there are many disadvantages of using a single database for microservices architecture. The first one is that it becomes difficult to scale up when your application starts growing because you have to upgrade all your hardware resources at once. If you have multiple databases then you can scale them up individually as demand increases, which makes it easier to add more capacity when needed.
Another disadvantage is that if your application needs different types of data then it might be better to use multiple databases instead of creating multiple schemas on a single database, but this has its own disadvantages as well.
One-to-many relationship in Microservices:
When developing microservices architecture, you will most likely come across relationships between entities like orders and customers or products and categories etc., where an order may have several customers or an item can belong to more than one category etc. A good example would be a bookstore website where each book can have multiple authors and each author can write multiple books etc.